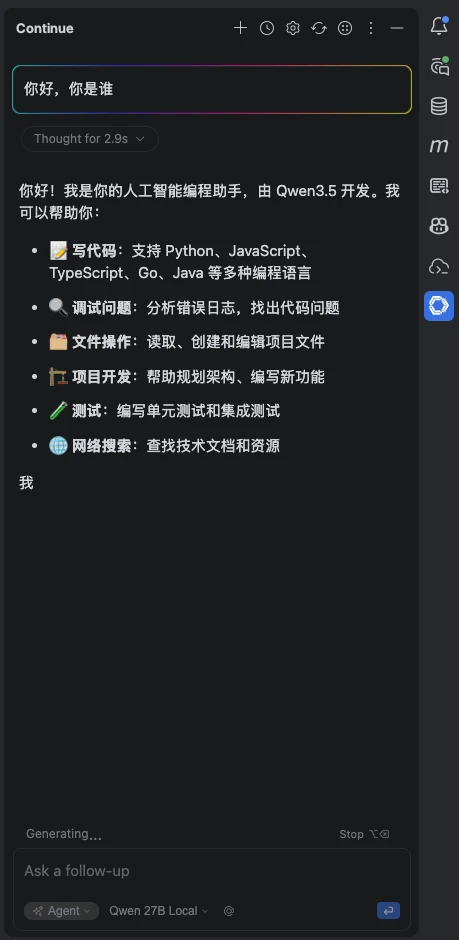
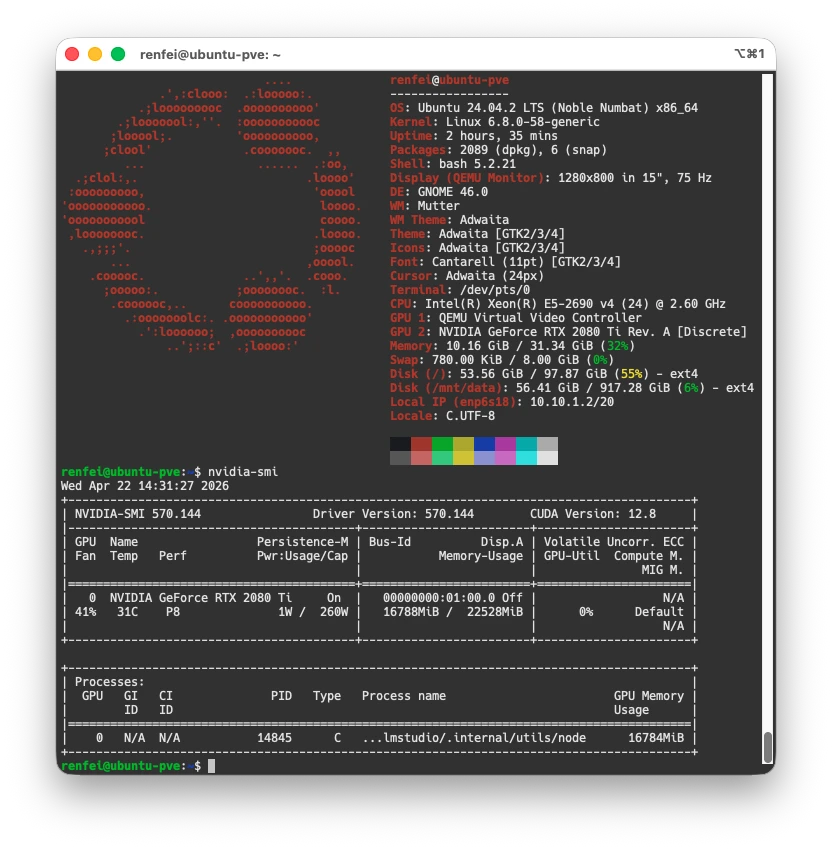
Codex额度不够用?等待恢复额度的时间怎么办?我想着自己之前有一个 RTX 2080 Ti 显卡,自己跑模型临时用一下怎么样,然后我就跑通了下面的链路: IntelliJ IDEA -> Continue -> LM Studio(macOS) -> LM Link -> LM Server(Linux)-> CUDA(RTX 2080 Ti 显卡) 基础环境准备 首先你需要一个能运行大模型的环境,我的是 NVIDIA GeForce RTX 2080 Ti 显卡,并且在 Ubuntu 已经安装好了英伟达的 CUDA、驱动,可以执行 nvidia-smi 命令。 由于本文的重点不是英伟达显卡安装驱动和CUDA,所以我不再赘述具体安装过程,认为读者已经具备基础的运行环境,我这里的运行环境如下(PVE虚拟机中):
- Intel(R) Xeon(R) E5-2690 v4 (24) @ 2.60 GHz
- 32G运行内存
- Ubuntu 24.04.2 LTS (Noble Numbat) x86_64
- NVIDIA-SMI 570.144
- Driver Version: 570.144
- CUDA Version: 12.8
- NVIDIA GeForce RTX 2080 Ti 22G
 安装LM Studio 在安装 LM Studio 时,我分为两个,一个是我在 macOS 上的客户端,另一个是在我服务器上的服务端。
安装LM Studio 在安装 LM Studio 时,我分为两个,一个是我在 macOS 上的客户端,另一个是在我服务器上的服务端。
- macOS 上的客户端:安装非常简单,下载以后拖拽到本地就可以,这里不做赘述。
- Linux 上的服务端:执行安装脚本命令:curl -fsSL https://lmstudio.ai/install.sh | bash
Linux 服务端 在安装完成以后,我们就可以通过下面的命令启动服务了:
# 启动守护服务
lms daemon up
# 启动服务器服务
lms server start
# 查看运行状态
lms statusLM Link 这个 LM Link 可以让你调用远端模型跟本地模型一样方便,类似内网穿透服务,目前免费。 官网申请:https://lmstudio.ai/link 我申请秒过,功能立即开通了,马上有使用权限了 然后回到我们的 Linux 服务器上,执行启用命令:
# 启用 LM Link
lms login
lms link enable
# 查看 Link 状态
lms link status然后,在我们自己的管理界面上就可以看到了:https://lmstudio.ai/settings/lm-link 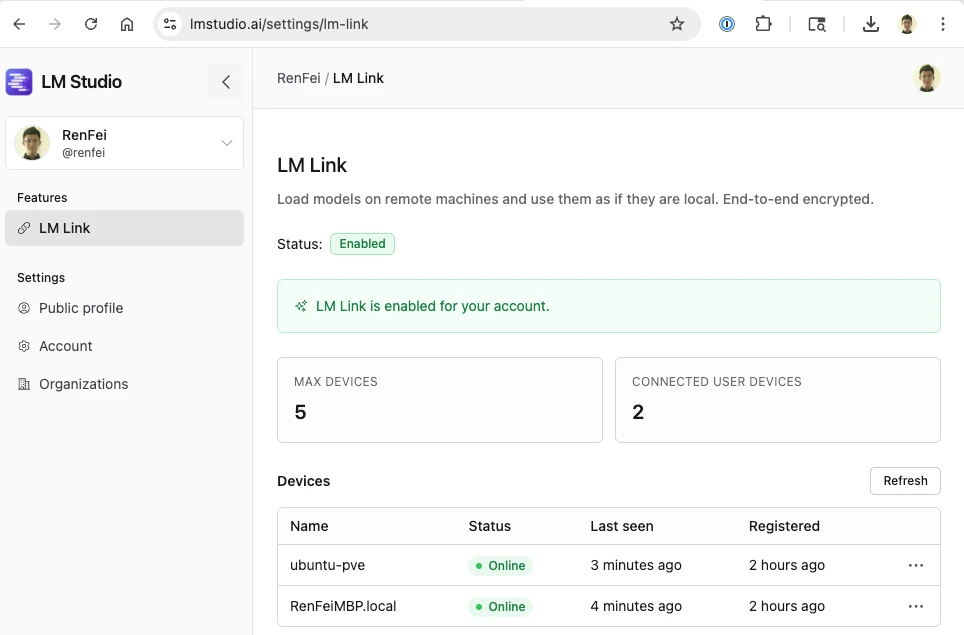
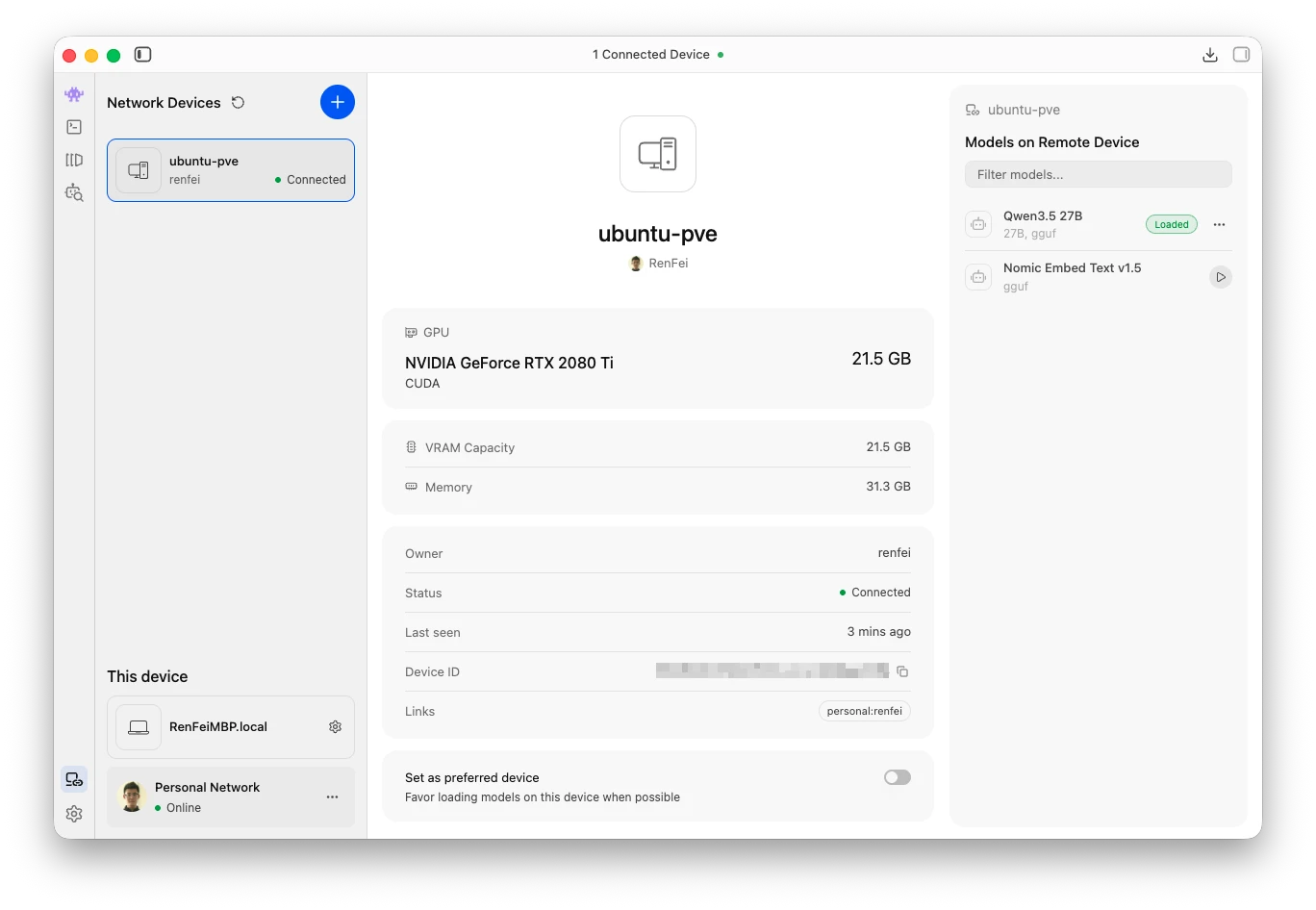 下载模型 我的22G现存,非常适合运行 qwen3.5-27b-gguf 在 Linux 服务器上执行下载命令:
下载模型 我的22G现存,非常适合运行 qwen3.5-27b-gguf 在 Linux 服务器上执行下载命令:
# 查看已有模型
lms ls
# 下载指定模型
lms get qwen/qwen3.5-27b
# 加载指定模型
lms load qwen/qwen3.5-27b本地调用 然后我们回到 macOS 上的 LM Studio,由于是登录的同一个账号,在顶部加载模型那已经可以看到我服务器上的 qwen3.5-27b 模型了,我们选择加载这个模型,就可以像调用本地模型一样,调用远端的模型了 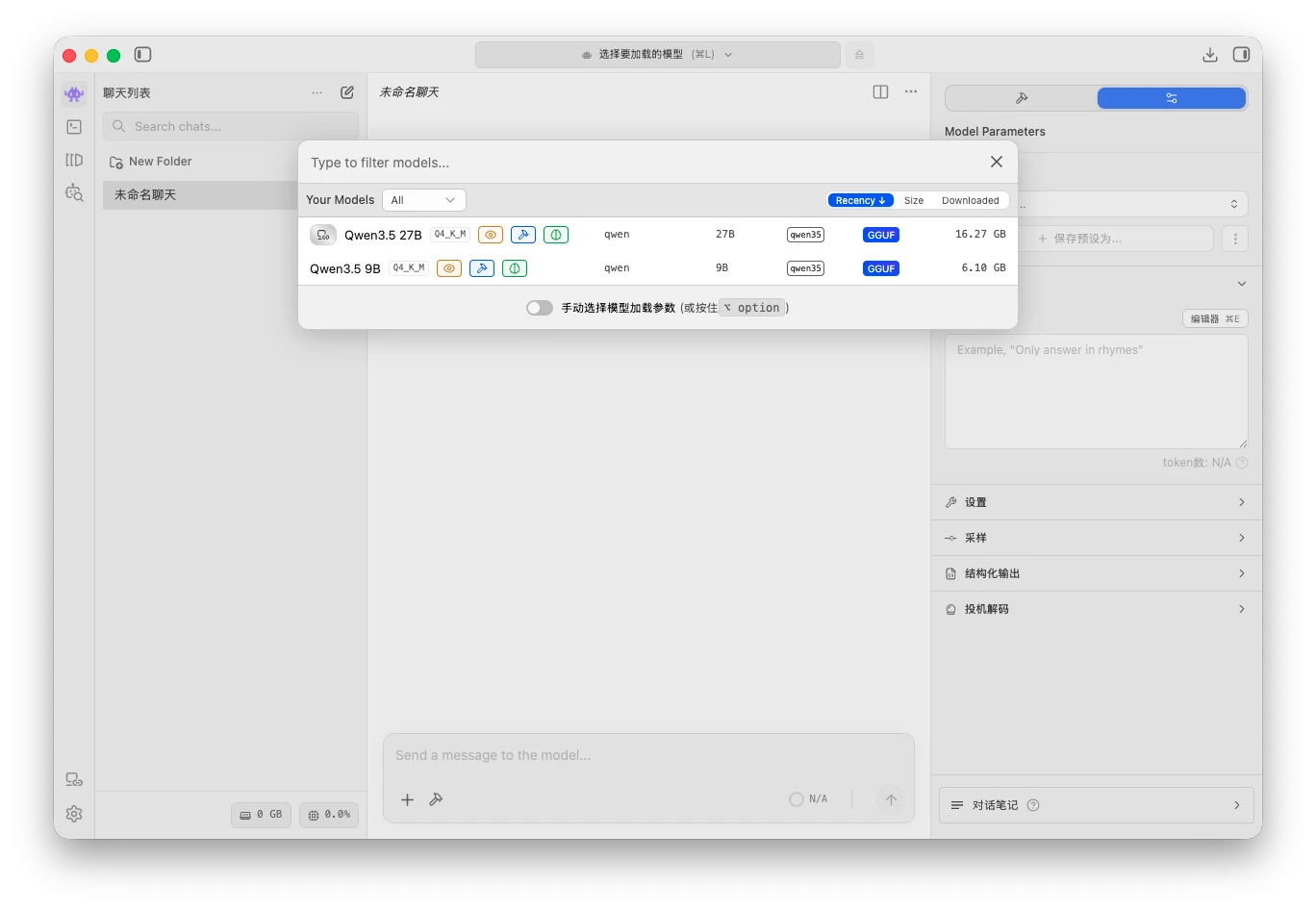
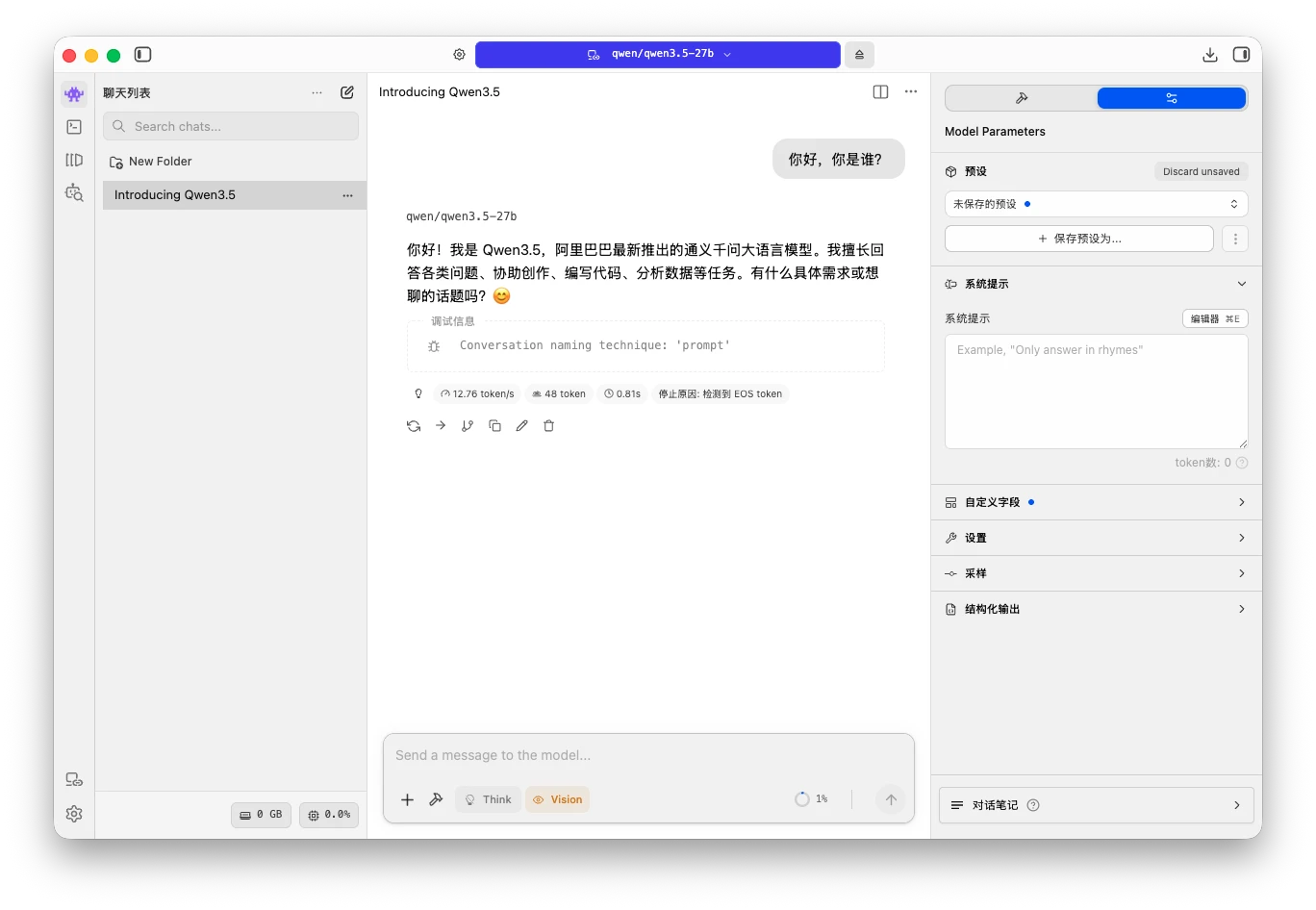 开启本地服务接口 然后我们还需要点击第二个 Developer 开发者选项,开启本地服务,就可以在本地通过接口访问了,例如访问:http://localhost:1234/v1/models,会列出模型列表
开启本地服务接口 然后我们还需要点击第二个 Developer 开发者选项,开启本地服务,就可以在本地通过接口访问了,例如访问:http://localhost:1234/v1/models,会列出模型列表 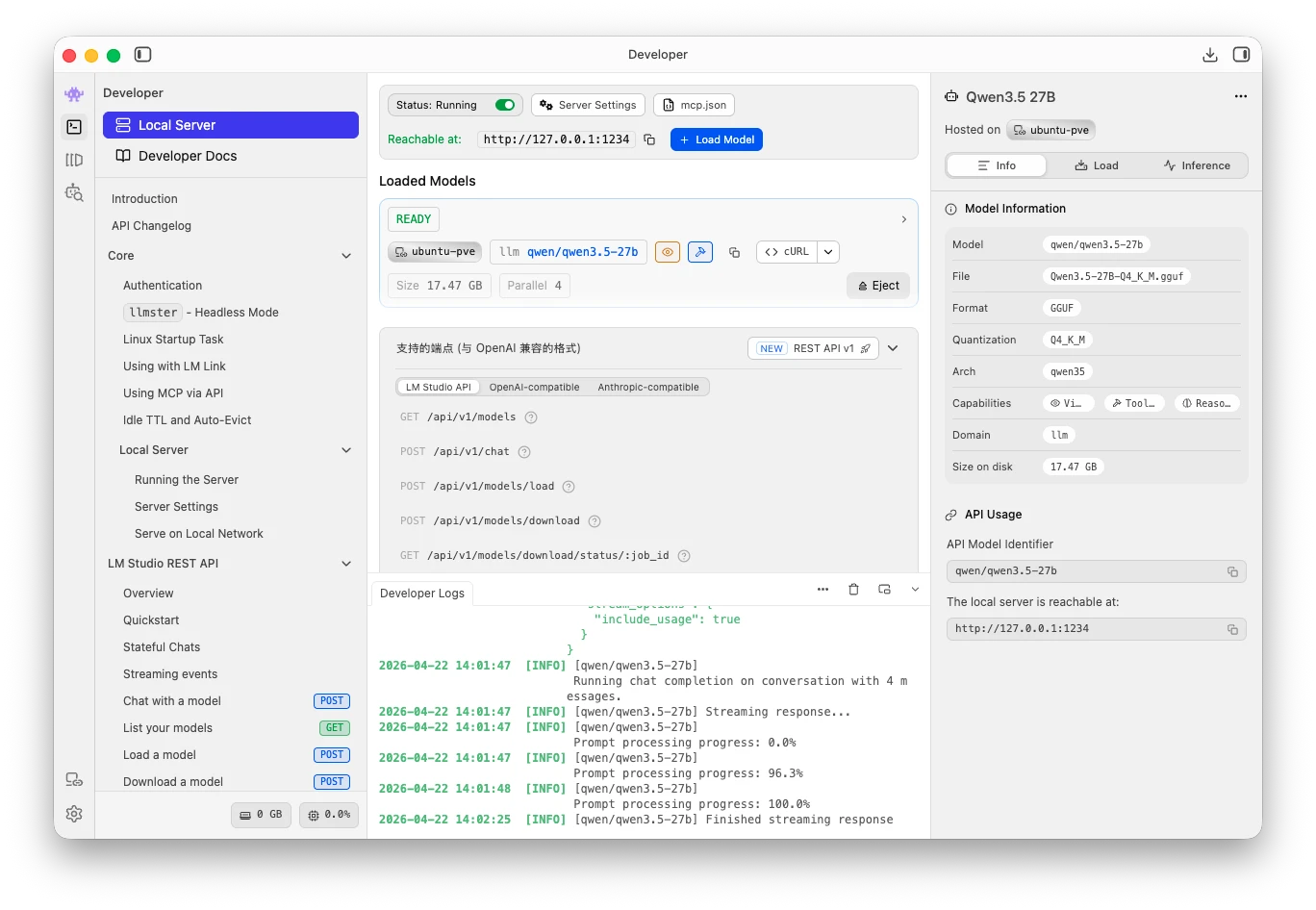 IntelliJ IDEA 调用 在 IDEA 中安装 Continue 插件,这个插件可以自定义端点使用自己的本地模型。 在 Continue 插件中,选择 Local Config 右侧的小齿轮,会打开配置文件,我们写入:
IntelliJ IDEA 调用 在 IDEA 中安装 Continue 插件,这个插件可以自定义端点使用自己的本地模型。 在 Continue 插件中,选择 Local Config 右侧的小齿轮,会打开配置文件,我们写入:
name: Local LM Studio
version: 1.0.0
schema: v1
models:
- name: Qwen 27B Local
provider: openai
model: qwen/qwen3.5-27b
apiBase: http://127.0.0.1:1234/v1
apiKey: lm-studio
roles:
- chat
- edit
- apply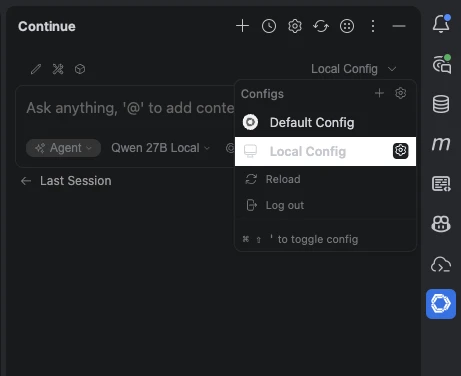 到这里,我们就可以用我们自己的模型开始 Vibe Coding 了,实现本地模型的 Token 自由~
到这里,我们就可以用我们自己的模型开始 Vibe Coding 了,实现本地模型的 Token 自由~