Hadoop入门教程(一):Hadoop 是什么 Hadoop 由什么组成
在上一大章节我们讲了大数据仓库的概念,我们了解了数仓的建设思想,接下来我们就开始让我们的思想慢慢变为现实,承载这一切的基础就是 Hadoop 生态圈中的各种大数据组件,慢慢形成我们的大数据仓库和平台。
共 167 篇文章
在上一大章节我们讲了大数据仓库的概念,我们了解了数仓的建设思想,接下来我们就开始让我们的思想慢慢变为现实,承载这一切的基础就是 Hadoop 生态圈中的各种大数据组件,慢慢形成我们的大数据仓库和平台。

在 SQL 语句中,LIKE 操作符用于在 WHERE 子句中搜索列中的指定模式。在实际使用中也是非常常见的查询方式,很多同学经常使用 % 百分号来进行模糊搜索,但其实还支持很多种查询模式。
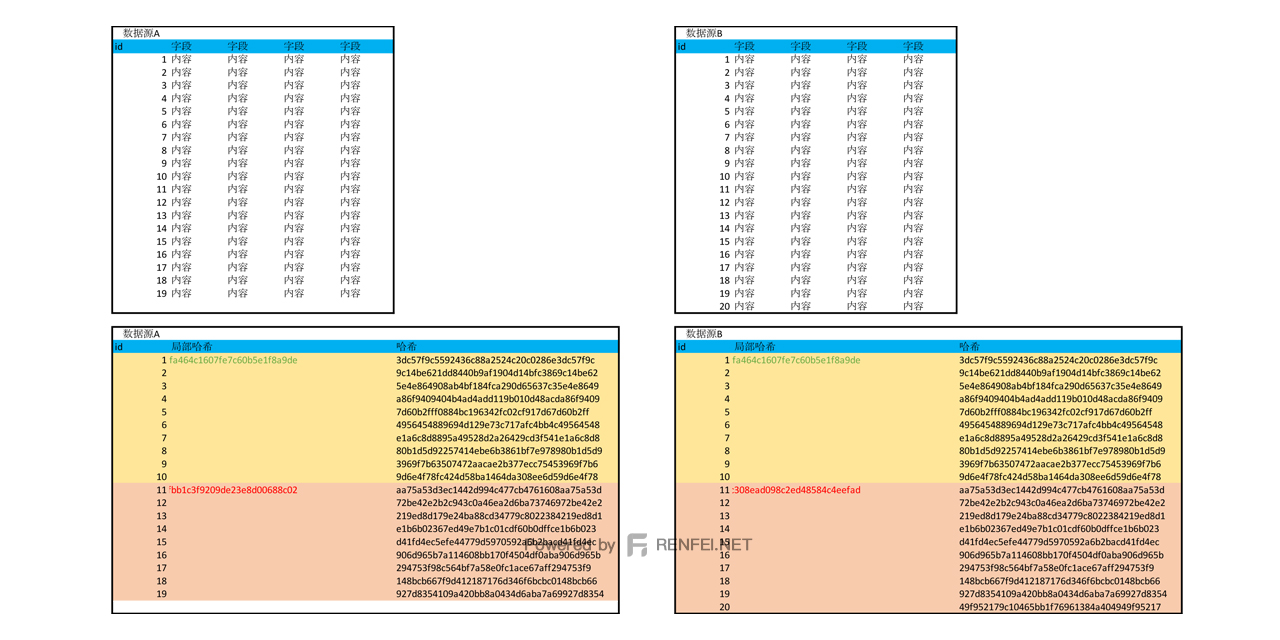
在上一篇文章中我们通过对每条数据的所有字段进行了哈希摘要,将几十个字段摘要成了一串哈希值,加快的我们的对比速度,但这只是将字段进行了压缩,数据的数量还是没有被压缩,如果有几十亿条数据,我们还是不能快速的找到变化的数据。
上一篇文章我们了解了事实表、维度表和星型模型、雪花模型,除了这些在行业中还有一些专业名词需要了解,本篇文章将带你了解大数据行业“黑话”全量表、增量表、拉链表、流水表、快照表都是什么。可能下面的一些内容理解不了,等到搞 hive 的时候就知道了,先了解一下基本的知识。

在上一篇数据仓库分层设计中,我们还提到了各个层除了原始表还进行了一些加工,在加工的时候还提到了事实表、维度表,本文带你粗略的理解一下事实表、维度表,数据模型中的星型模型、雪花模型。

随着数据随时间流入我们的数据仓库以后,数据的种类和数量将越来越庞大,如果不加以治理和设计,我们查询取用数据时将遇到很大的问题,所以就需要对数据仓库进行设计,让数据分门别类的放到自己应该去的地方,方便我们日后随时调用查取。

本文作为开启大数据技术入门级系列教程首篇文章,我们使用的任何大数据组件和工具其实都是在解决数据的问题,而数据就需要通过数据仓库存取,无论你使用什么样的技术架构都离不开数据仓库,所以第一篇文章先了解一下什么是数据仓库,以及数据仓库和数据库有什么区别。

包括大数据数据仓库的概念、Hadoop入门教程、Zookeeper入门教程、Hive入门教程、Flume入门教程、Kafka入门教程、Hbase入门教程、Sqoop入门教程、Oozie入门教程、azkaban入门教程、Kylin入门教程、CDH入门教程、Impala入门教程、Hue入门教程、ClickHouse入门教程、Kettle入门教程、Ambari入门教程、ELK入门教程、Scala入门教程、Flink入门教程

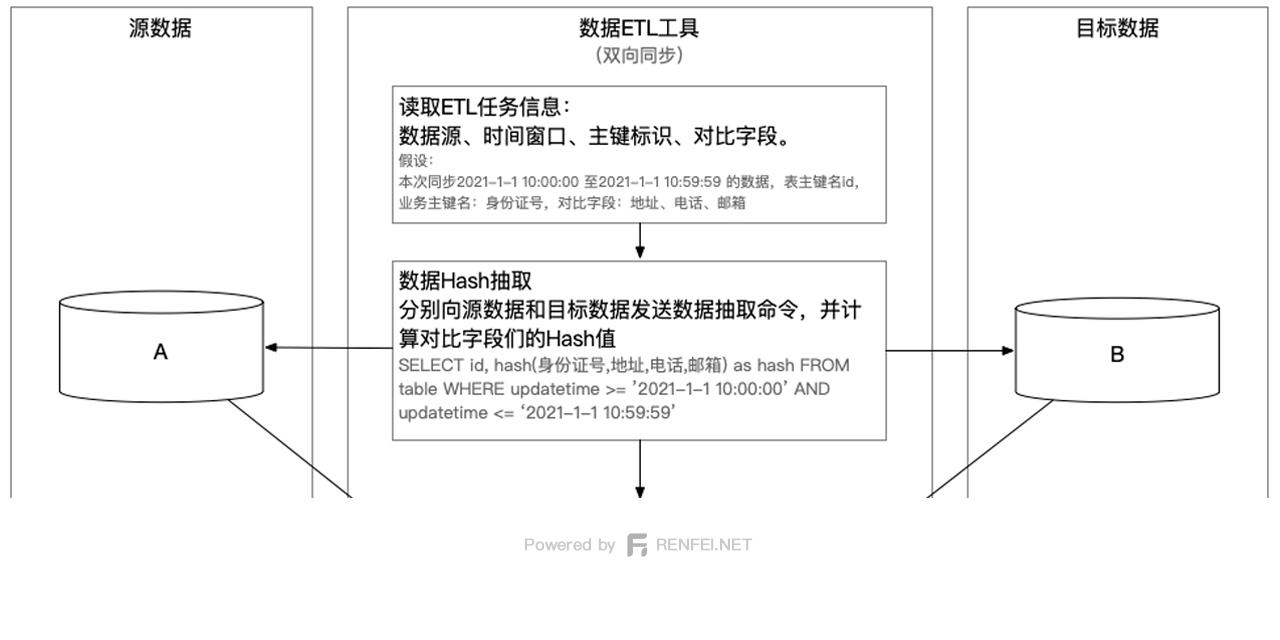
说到大数据仓库技术,不得不提ETL,ETL一词较常用在数据仓库,但其对象并不限于数据仓库。可以说是非常重要的一个环节,简单介绍一下ETL数据抽取比对的方法。
我的主站 Spring Boot 与 Discuz! 论坛进行了打通,实现了同步的登录登出,并可以将 Discuz! 论坛中会员的数据回显到我的主站中,并且我对之前开源的 discuz-ucenter-api-for-java 进行了部分修改,以适应当下 Spring Boot 的风格。
